Colloquially using Random
The communication of ideas is essential. Whether building on terms previously heard, discussing ideas with peers, or labelling experiences, language plays a vital role in understanding new concepts. Kaplan, et al. (2009) suggest that statistical words with everyday counterparts can endorse incorrect assumptions about statistical concepts. For example, the following is a Tweet calling for “random” facts:
What’s the most random fact you know?
— brittany packnett cunningham ain’t here for real. (@MsPackyetti) January 28, 2020
I mean RANDOM random.
Some of the more interesting replies include:
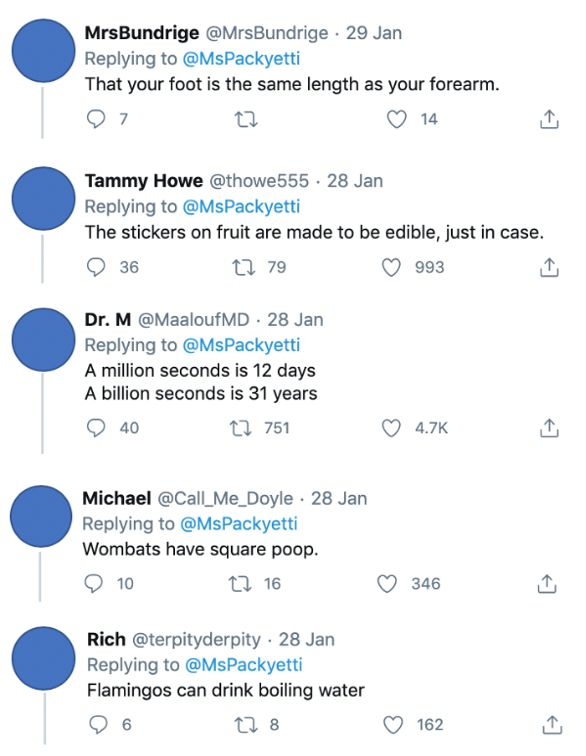
See some discussion examples!
The use of “random” here refers to something being unusual or surprising. With this in mind, it is then understandable that someone might deem a patterned sequence of heads and tails as being not random – HTHTH appears to be neither unusual nor surprising. The term random is homonymous – it holds more than one meaning or definition or use (Kaplan et al., 2009). There are a few cases of this in statistics (as well as other fields, too); average, margin, mean, and normal are some examples.
This site has been created as part of my PhD thesis on perceptions of randomness. I am always keen for feedback, so please email me any thoughts you have via amy.renelle@auckland.ac.nz. Thank you to my supervisors, Dr. Stephanie Budgett and Dr. Rhys Jones, for their guidance throughout my project. I would also like to thank Anna Fergusson for her help inspiring and creating this website. You can find the references for this site here.